这一期的主要内容是初探 写时复制(Copy On Write) 技术,该技术在 Linux 系统创建子进程时被使用到。众所周知,我们可以通过 fork 函数来创建一个子进程。该子进程可以说是其父进程的一个副本,继承了父进程很多属性,包括代码空间和数据空间
传统的做法
考虑最一般的创建子进程的方法,子进程需要将父进程的数据空间等信息拷贝到属于自己的内存空间中去,这样才能保证自己在操作数据(特别是写数据)时不会影响到父进程。所以每次创建新的子进程时都需要进行数据空间(包括数据段、堆栈段)的拷贝,以保证父子进程之间的数据段和堆栈是相互独立的。而代码段由于不可写(不会被修改),故没必要拷贝,父子进程共用一块代码空间即可
写时复制的引入
相信你也发现了这么做的缺点,拷贝数据空间是要花时间的。如果父子进程之后不对数据空间进行写操作(不修改数据),那子进程就没必要再花时间来拷贝父进程的数据了,子进程直接将自己的数据空间映射到父进程的数据空间去,便可大大降低创建进程的代价(尤其对于将执行 exec 系列函数的子进程,这里不进行展开)。
或许你又会问,CPU 怎么知道父进程/新建的子进程之后会不会对数据空间进行写操作?预测吗?那万一猜错了,实际上进程要写数据又该怎么办?…… 放过 CPU 吧,人家做分支预测都已经忙不过来了,哪还有心情来预测这个
实际上,Linux 采取了一种折中的方式。fork 创建进程时,先把子进程数据空间映射到父进程的数据空间去,不过需要将父子进程对于数据空间的访问权限都修改为只读(也有例外,后面代码分析时会提及)。以后如果其中一个进程(父进程或子进程)要写数据了,CPU 把要写入的地址拿来一看,发现地址只读,于是抛出一个页错误的异常,然后去运行异常对应的处理程序。该处理程序就会拷贝触发页错误的内存页到新的内存区域去,并重新建立进程对于该页的映射,使其映射至新创建的”副本”页,最后通知 CPU 重新执行写操作。这就是所谓的写时复制技术,真就是在写的时候才进行复制
写时复制的优缺点
- 优点:减少不必要的资源分配,提高创建进程的效率
- 缺点:进程创建完毕后,如果父子进程都还要写数据,将会产生大量页错误
fork.c
对写时复制技术有个概念之后,再来看其实现细节就会好理解的多了,同样,一些涉及到内存管理的函数现在只需知晓其功能。当在程序中调用 fork 创建子进程时,实际通过系统调用 sys_fork 完成,其定义在system_call.s 中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| /* kernel/system_call.s Line 207 */
.align 4
sys_fork:
call find_empty_process
testl %eax,%eax /* 如果返回的任务号是负数,就直接返回 */
js 1f
push %gs
pushl %esi
pushl %edi
pushl %ebp
pushl %eax /* 压参并调用 copy_process */
call copy_process
addl $20,%esp
1: ret
|
可以看到一开始就调用了 find_empty_process 来寻找任务数组中没有被使用(空闲)的项,然后压参调用 copy_process 来拷贝一些父进程的属性并设置新进程自身的属性信息。find_empty_process 定义在 fork.c 末尾:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
long last_pid=0;
int find_empty_process(void)
{
int i;
repeat:
if ((++last_pid)<0) last_pid=1;
for(i=0 ; i<NR_TASKS ; i++)
if (task[i] && task[i]->pid == last_pid) goto repeat;
for(i=1 ; i<NR_TASKS ; i++)
if (!task[i])
return i;
return -EAGAIN;
}
|
copy_process
然后是核心函数 copy_process,从上面 sys_fork 的代码可以看出,在调用之前,还压入了部分参数,这些参数都将用于设置子进程属性。copy_process 函数的参数很多,按照从下往上,从右往左的顺序来看,依次是执行系统调用指令(INT 0x80)时压入的 ss, esp, eflags, cs, eip;system_call 子程序执行时压入的 ds, es, fs, edx, ecx, ebx(system_call.s 83 ~ 88 行);执行 call sys_call_table(,%eax,4)(system_call.s 第 94 行)调用 sys_fork 时压入的返回地址 none;以及 sys_fork 中压入的 gs, esi, edi, ebp, eax(find_empty_process 函数的返回值,即空闲的任务号 nr)。下面是 copy_process 函数的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,
long ebx,long ecx,long edx,
long fs,long es,long ds,
long eip,long cs,long eflags,long esp,long ss)
{
struct task_struct *p;
int i;
struct file *f;
p = (struct task_struct *) get_free_page();
if (!p)
return -EAGAIN;
task[nr] = p;
*p = *current;
p->state = TASK_UNINTERRUPTIBLE;
p->pid = last_pid;
p->father = current->pid;
p->counter = p->priority;
p->signal = 0;
p->alarm = 0;
p->leader = 0;
p->utime = p->stime = 0;
p->cutime = p->cstime = 0;
p->start_time = jiffies;
p->tss.back_link = 0;
p->tss.esp0 = PAGE_SIZE + (long) p;
p->tss.ss0 = 0x10;
p->tss.eip = eip;
p->tss.eflags = eflags;
p->tss.eax = 0;
p->tss.ecx = ecx;
p->tss.edx = edx;
p->tss.ebx = ebx;
p->tss.esp = esp;
p->tss.ebp = ebp;
p->tss.esi = esi;
p->tss.edi = edi;
p->tss.es = es & 0xffff;
p->tss.cs = cs & 0xffff;
p->tss.ss = ss & 0xffff;
p->tss.ds = ds & 0xffff;
p->tss.fs = fs & 0xffff;
p->tss.gs = gs & 0xffff;
p->tss.ldt = _LDT(nr);
p->tss.trace_bitmap = 0x80000000;
if (last_task_used_math == current)
__asm__("clts ; fnsave %0"::"m" (p->tss.i387));
if (copy_mem(nr,p)) {
task[nr] = NULL;
free_page((long) p);
return -EAGAIN;
}
for (i=0; i<NR_OPEN;i++)
if (f=p->filp[i])
f->f_count++;
if (current->pwd)
current->pwd->i_count++;
if (current->root)
current->root->i_count++;
if (current->executable)
current->executable->i_count++;
set_tss_desc(gdt+(nr<<1)+FIRST_TSS_ENTRY,&(p->tss));
set_ldt_desc(gdt+(nr<<1)+FIRST_LDT_ENTRY,&(p->ldt));
p->state = TASK_RUNNING;
return last_pid;
}
|
以上代码需要注意的地方有两点:
- 新进程 task_struct 结构体与其内核栈实际在同一内存页,从
p->tss.esp0 = PAGE_SIZE + (long) p; 可以看出,不过 task_struct 从页面底端开始,而内核栈从页面顶端开始往低地址生长
- fork 函数调用对父进程返回正整数
return last_pid;,对子进程返回 0 p->tss.eax = 0;,在该函数得到体现
copy_process -> copy_mem
我们正一步一步深入 fork 函数的实现细节,且即将接触到写时复制的核心。copy_process 中调用了一个非常关键的函数 copy_mem,该函数接收两个参数,分别为由 find_empty_process 选出的空闲任务号及新进程的 task_struct 结构体指针:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
int copy_mem(int nr,struct task_struct * p)
{
unsigned long old_data_base,new_data_base,data_limit;
unsigned long old_code_base,new_code_base,code_limit;
code_limit=get_limit(0x0f);
data_limit=get_limit(0x17);
old_code_base = get_base(current->ldt[1]);
old_data_base = get_base(current->ldt[2]);
if (old_data_base != old_code_base)
panic("We don't support separate I&D");
if (data_limit < code_limit)
panic("Bad data_limit");
new_data_base = new_code_base = nr * 0x4000000;
p->start_code = new_code_base;
set_base(p->ldt[1],new_code_base);
set_base(p->ldt[2],new_data_base);
if (copy_page_tables(old_data_base,new_data_base,data_limit)) {
free_page_tables(new_data_base,data_limit);
return -ENOMEM;
}
return 0;
}
|
该函数同样有两点需要注意:
- Linux 0.11 还不支持代码段和数据段分立,且数据段长度应大于代码段长度,故有
old_data_base != old_code_base 和 data_limit < code_limit 这样的检查存在
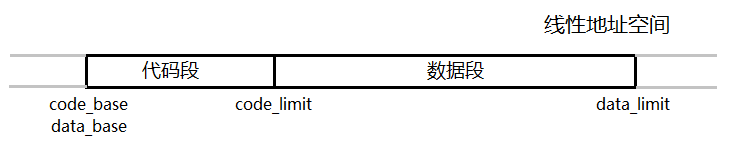
- Linux 0.11 中最多支持 64 个进程(包括 0 号进程)。因为 32 位线性地址空间大小为 4G,所以分配给每个进程的线性地址空间大小为 4G / 64 = 64 MB。故进程的代码和数据段在线性地址空间中的起始地址为 任务号 * 64MB
有关进程代码段数据段的布局如下图:

故现在所说的数据空间实际上也包含了代码空间
copy_process -> copy_mem -> copy_page_tables
copy_mem 函数末尾调用了 copy_page_tables,正是该函数构建了写时复制技术的框架。其功能就是建立子进程数据空间到父进程数据空间的映射,并且将父子进程对于数据空间的访问权限都设置为只读。想要实现这些效果,那是不是得操作页目录项和页表项呀?没错,由分页机制可知,建立线性地址空间到物理地址空间的映射从本质上来说就是构建页目录和页表,子进程通过拷贝父进程数据空间对应的页表就能将自己的数据空间也映射到同一片物理内存区域。复制的过程中再修改一下页表项(PTE)中的 R/W 位,就能达到控制访问权限的目的了
copy_page_tables 就是按照这种思路实现的,其接收三个参数,from 是父进程代码/数据段基址(线性地址),to 是新进程代码/数据段基址(线性地址),size 是数据段的段限长(即父子进程共享的内存长度)。而线性地址是由页目录表索引(高 10 位)、页表索引(中间 10 位)和页内偏移(低 12 位)拼接成的,因此通过位移操作便可获得页目录及页表索引,进而访问/修改页目录项、页表项(如果对于分页机制的概念比较模糊,建议先花点时间看看 保护模式 一文的分页机制部分)。下面是对代码的分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
int copy_page_tables(unsigned long from,unsigned long to,long size)
{
unsigned long * from_page_table;
unsigned long * to_page_table;
unsigned long this_page;
unsigned long * from_dir, * to_dir;
unsigned long nr;
if ((from&0x3fffff) || (to&0x3fffff))
panic("copy_page_tables called with wrong alignment");
from_dir = (unsigned long *) ((from>>20) & 0xffc);
to_dir = (unsigned long *) ((to>>20) & 0xffc);
size = ((unsigned) (size+0x3fffff)) >> 22;
|
from 和 to 给出的线性基址应该是 4MB 对齐的(因为一个页目录项管理 4MB 的物理内存),函数首先就检验了一下对齐情况
接着计算源地址/目的地址对应的页目录项指针,需要注意的是,页目录是从物理地址 0 开始存放,且每个页目录项占 4 字节。所以在计算线性地址对应的页目录项指针时,理论上应该先将线性地址右移 22 位得到页目录索引,再乘以 4 得到页目录项的地址,相当于 (a >> 22) << 2 (假设 a 是线性地址)。然而这里选择了另一种表现形式,直接右移 20 位,再通过和 0xffc 进行与运算以保证低两位是 0(4 字节对齐)
在计算 size 的时候,右移 22 位表示除以 4MB,并且进行了舍入(size + 4MB - 1),例如当传入的 size 是 4.01MB 或 8 MB 时,计算结果都为 2(表示涉及两个页目录项)
接下来就要开始复制页表项了,通过嵌套 for 循环完成,并且设置每个页表项的 R/W 字段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| for( ; size-->0 ; from_dir++,to_dir++) {
if (1 & *to_dir)
panic("copy_page_tables: already exist");
if (!(1 & *from_dir))
continue;
from_page_table = (unsigned long *) (0xfffff000 & *from_dir);
if (!(to_page_table = (unsigned long *) get_free_page()))
return -1;
*to_dir = ((unsigned long) to_page_table) | 7;
nr = (from==0)?0xA0:1024;
for ( ; nr-- > 0 ; from_page_table++,to_page_table++) {
this_page = *from_page_table;
if (!(1 & this_page))
continue;
this_page &= ~2;
*to_page_table = this_page;
if (this_page > LOW_MEM) {
*from_page_table = this_page;
this_page -= LOW_MEM;
this_page >>= 12;
mem_map[this_page]++;
}
}
}
invalidate();
return 0;
}
|
至此,对于 fork 创建子进程及写时复制技术的分析就告一段落了,fork.c 中的 verify_area 函数以及 CPU 遇到页错误的处理方式(写时复制技术余下部分)还没有提到,等到 mm 模块再做记录 ~